You can benefit from a large number of existing applications.
In a collaborating group?
Groupsheets can probably make your life a lot easier.
We help groups make effective use of AI-generated content.
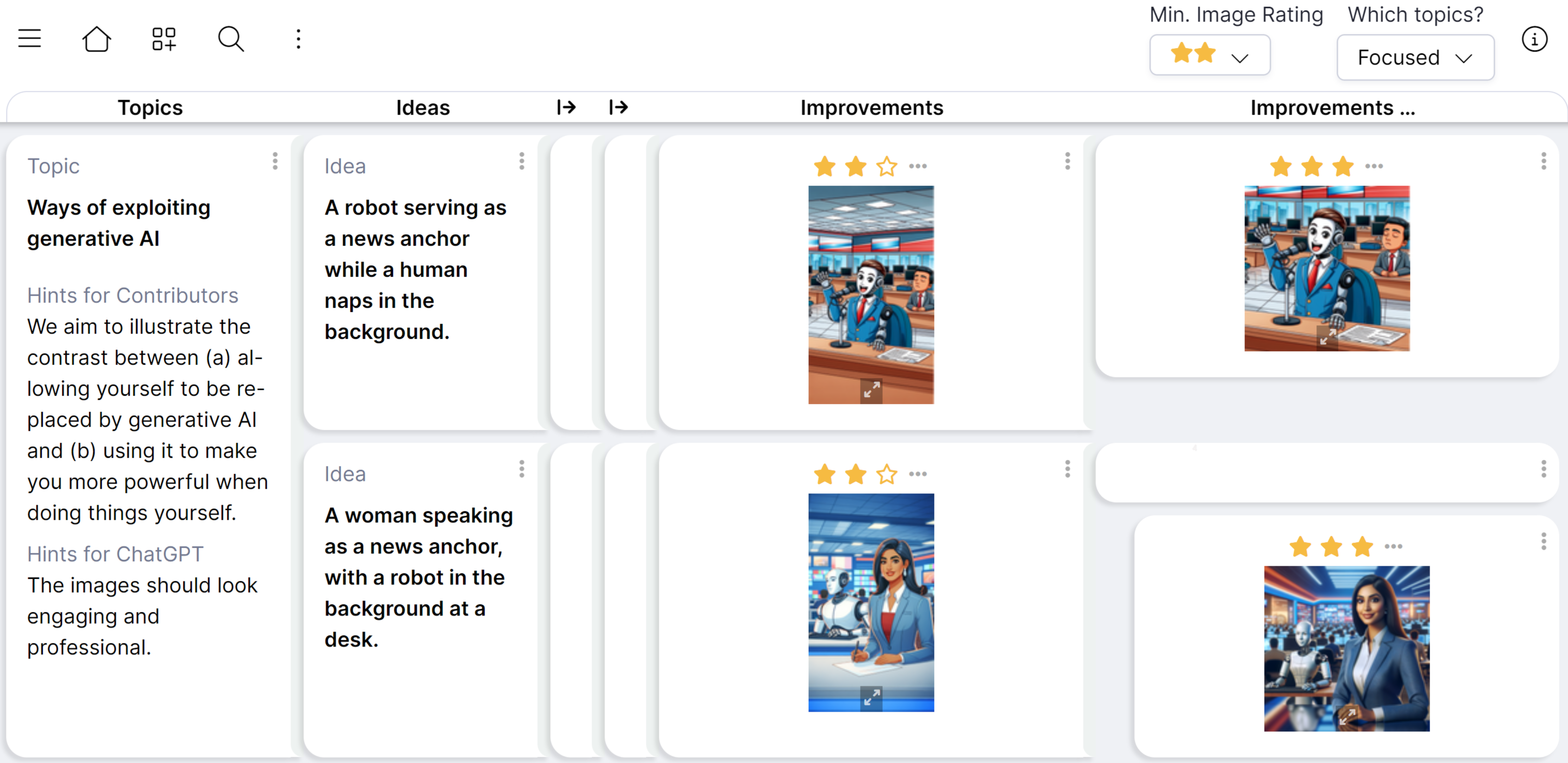
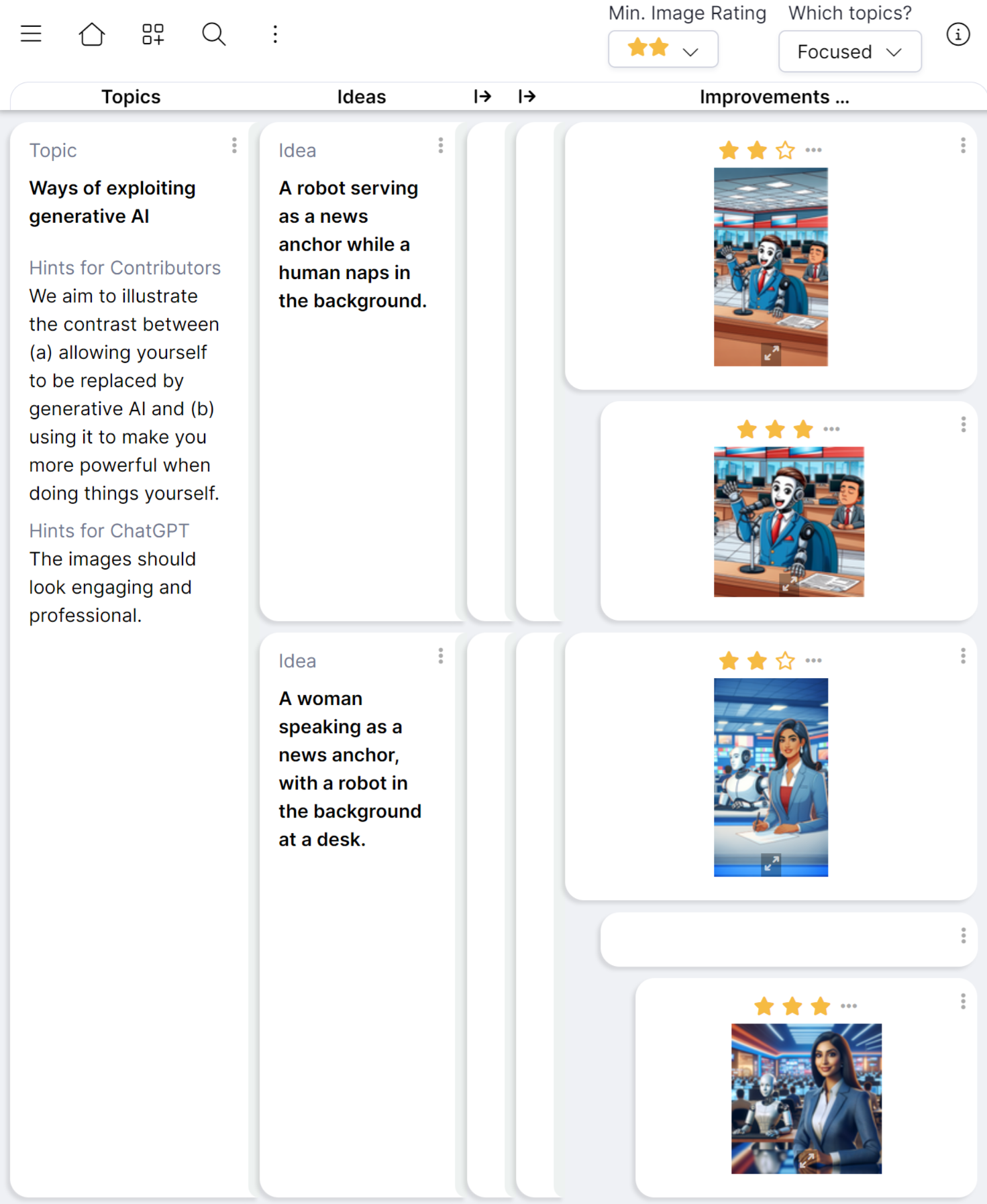
COLL-E: A Collaborative Web App for DALL-E 2 and DALL-E 3
COLL-E is the first deployed groupsheet that explicitly supports processing of AI-generated content.
It was introduced publicly for the first time at the CHI 2023 conference in Hamburg (23–28 April).
Since DALL-E 3 became available for applications in early November, COLL-E has been extended to exploit the combined strengths of DALL-E 2 and DALL-E 3.
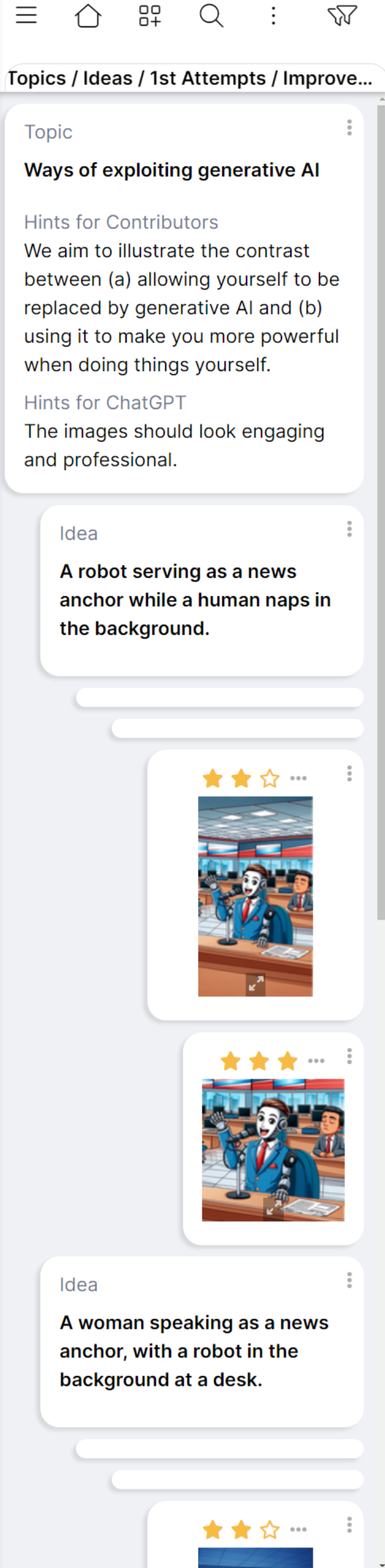
Screenshot of COLL-E being used by several contributors to generate images for a slide presentation about generative AI.
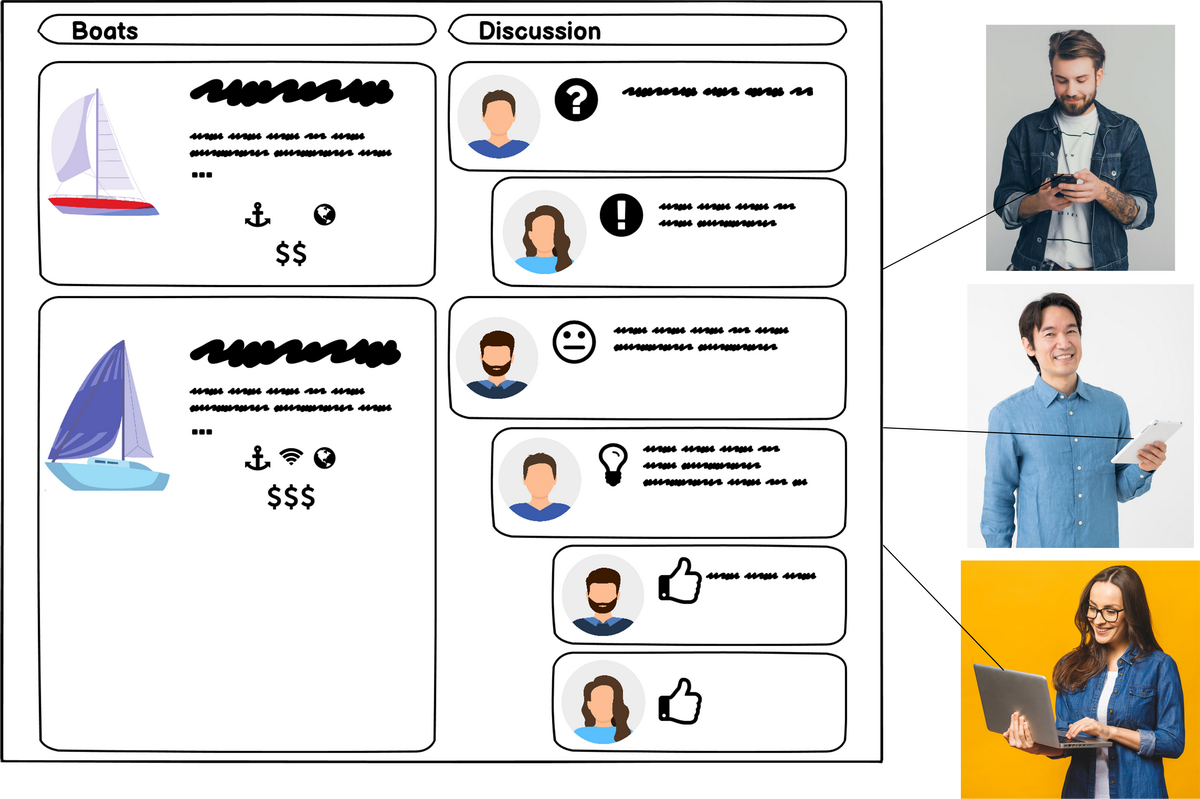
A groupsheet presenting content about possible boats to rent so that a group of friends can frictionlessly choose one of them.
COLL-E is realized within the general groupsheets platform.
Groupsheets provide a straightforward way of making content available to groups of people so that they can easily communicate, collaborate, and make decisions on the basis of the content.
Groupsheets have been deployed in a wide range of application scenarios.
Because of the current urgent need for interaction methods that help groups to deal effectively with AI-generated content, Contraction's current focus is on this type of application.